
覃子恒 复旦大学在读研究生 见知数据科技 (Xencio Data Technology)实习生
1、 研究方向概述
前段时间开始接手一项有关自然语言处理的需求,同时准备设计一系列的解决方案。需求大体上是说,给定一个对手方名称,我们要通过一些算法自动提取、拆分其中的有用信息。
举个例子,假设对手方名称是:
应付账款-上海见知数据科技有限公司徐汇分公司张三
那么我们第一步可以提取如下信息:
- 应付账款:其他信息
- 上海见知数据科技有限公司:公司主体
- 徐汇分公司:分支机构信息
- 相关人员:张三
第二步,对于公司主体,可以提取:
- 地理位置:上海
- 公司特有名称:见知
- 经营范围:数据科技
- 法律类型:有限公司
一般来说,完整规范的公司名称,人工都可以比较容易地拆分成这四个部分,有些不规范的,也只是缺其中一部分。
讨论了一下,我决定从将第一步和第二步拆成两个阶段完成,首先尝试给定一个公司主体全称,将其拆分为上述四个部分。
由于最近BERT预训练模型(一种深度神经网络模型)比较火,精度也比较高,因此我们打算从最基本的BERT模型做起,训练集和测试集暂时只选取最规范的公司名称。
在做模型之前,我也调研过一些主流的实体识别和分词、实体识别工具包,比如foolnltk、hanlp等,发现工具包虽然各有各的特色,但是对于针对这四部分的序列标注,用起来效果挺糟糕的——主要是公司特有名称和经营范围经常分不开——其实也能理解,毕竟这些模型都是训练自人民日报的训练语料,也不是本任务特化的模型,精度低这是难免的。
首先展示一下最后得到的模型效果,这种奇怪的公司名称肯定是不在我的训练集里,但是模型一样很好地识别了。

2、 基础数据获取
其实模型什么的都是前人已经翻来覆去玩过的模型,我这篇文章想讲的并非如何训练模型,而是如何根据本次任务的特性获取低成本但高质量的数据进行训练。
这个其实是一开始稍微困扰了我一段时间的问题,本来讨论下来是说随便造一些标签和数据,错了也没关系,只要模型相对正确地标注它就可以了。不过我想既然是要应用在真实数据上,还是造一些真实数据比较好。
但是神经网络模型非常庞大,训练集太少效果肯定是不好的,而人工标注数据明显不可能。
假如我能用很低的成本获取大量的虚拟标注数据训练了一个准确率较高的模型,那么接下来我可以用训练好的模型进一步标注未标注的真实数据、优化模型,这样就有了不断迭代下去的基础。
既然是要获取四部分的数据,首先明确这四部分的性质:
地理位置:容易遍历,中国一共就那么多行政单位,全拿一遍出来也不是什么难事。由于前段时间正好做了一个大众点评的爬虫,恰好爬取了该网站上的城市列表,然后手工去掉区级的部分,这样就很容易地得到了一些很高质量的地理位置字段了(共2435个)。
(这里吐槽一下,那个页面上没有港澳台和新疆的,需要的话得自己想办法,我另外爬了新疆的)

法律类型:这个就更少了,我只选了有限公司、股份有限公司、有限责任公司三种。
公司特有名称:直接百度了一下公司名大全,发现有人整理了一个列表,果断爬下来用,稍微清理了一下低质量的部分,一共697个。

最后也是最难获取的是经营范围了,首先这部分量不能太少,要获取真实的只能通过人工筛选或者分词,但分词又分不准,这就很尴尬了……这里无论如何都是要么牺牲精度要么牺牲数量。
经过权衡我决定还是牺牲数量(事实证明这个决定还是挺正确的,待会说),所以我采用了粒度比较小的fool分词,配合一个github上有人开源出来的480万条公司名称,根据一定的规则剔除较为容易识别的地理位置、法律类型,再通过nz标签和一系列其他规则区别特有名称和经营范围。
(当然会有很多错的,我的原则是宁可错杀也尽量不要有漏网之鱼,毕竟人工标注成本太高了)
最后经过去重,大概有将近10万条吧(还是有很多漏网之鱼),但是我也没管了,10万条显然太多了。我之后要用这些进行组合,如果全组合的话每有一个经营范围,就可以造出2435*697*3≈500万个虚拟公司名,实在是太多啦(实际上我最后训练集只有30万条)。

于是懒惰如我,就挑选了最前面的767条(这个数字是随便选了一部分然后统计的,没什么特别的意义,硬要说的话我打算让经营范围数量和特有名称数量在一个量级上),同样进行人工修正来保证质量。
但是就算这样,如果使用全组合,训练集也过于庞大,基本上电脑都受不了吧,30万条数据在我的RTX2080s上训练10个epoch都要30多个小时,但又要保证每个部分的多样性,所以不进行筛选是不行的。
3、 训练集获取
接下来就是组合四个部分,得到训练集了。刚才也说了,不筛选是不行的,但是怎么筛选呢?
首先,在地名上我并没有吝啬,2435条都用上了,但是特有名称和经营范围的选取就得稍微思考一下了。
我脑子里假设了一种很理想的情况:
- 首先,特有名称全都是巨头企业,他们经营范围都很广;
- 其次,每个城市规模都差不多,所以特有名称数量也差不多,但每个城市特有名称的类别重合度不能太高。比如既然有上海见知数据科技有限公司,那我尽可能就不要有江苏见知数据科技有限公司,我觉得这样比较符合实际情况一些。
- 最后,我想让每个城市里不同的特有名称数量和每家公司涉及的经营范围总数乘积为经营范围总数。比如我一共有900个经营范围,每个城市选了30条不同的特有名称,那么每个公司我都会从900个经营范围里无放回地抽取30个经营范围。这也是为了保证多样性。
- 最后对每个特有名称,我仅指定一个法律类型,我有了上海见知数据科技有限公司,我同样不希望还出现上海见知数据科技股份有限公司。
最后用我的这种方法抽取了将近2000000个公司名称,我再从中打乱随机抽取了50万条,30万条训练,10万条验证,10万条测试。
这样看来,之前提到的有限精度牺牲数量还是非常合理的,训练集再大,没有足够的计算资源也是一种浪费。
4、 训练结果
使用别人写好的模型和没怎么调整过的参数训练了没几个epoch(batch size为4,epoch为5,这模型太耗显存了),结果就十分美好了:

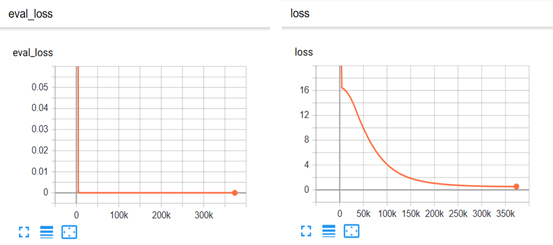
而模型实际上训练了1/4个epouch都没到,在验证集上的loss就几乎为0了,训练集倒是一直持续到最后loss还在下降:
不过对于不太规范的公司识别能力就比较差了:

时,这个模型非常耗费内存显存(显卡基本吃满,内存占4个G)。不过比较意外的是用显卡运行测试和用cpu运行差距不大。
所以接下来能做的事情也比较清楚了,除了想办法缩小模型降低消耗,还有一个就是调整训练集中的词顺序对应打上标签,造各种各样的数据。
总之数据造起来都很容易。任务变得复杂之后我们也不能指望那么高的准确率,但这无疑将大大降低人工标注的成本,起码现在对于标准公司就不太需要人工复核了。
最后再展示一个样例,如果直接用fool分词,这个标注方式实际上是无法识别对应的四个部分,中间两个只能通过人工修正,而训练后的bert模型则在训练集中没有中超利永、紫砂陶这两个词的情况下,很好地学习到了这两个部分对应的标签






